2025GCCCTF-misc-部分赛题出题记录和wp

2025GCCCTF-misc-部分赛题出题记录和wp
Tonglinggejimo前言
其实并不想出题,只想打比赛,但是被老师抓去出题了,哭😭
算了,写一个博客来记录下这次出题的过程吧,也是我第一次出题哦,也算是换了一个CTF的视角,只出了计小鸡的秘密和DNS Courier这两道题目,其他题目全是由校内其他师傅出的,如果出的题不好请见谅。
现在GCCCTF的所有题目均已上NSSCTF平台,可以在平台复现做题,感谢NSSCTF平台的支持🙏,这个平台很好哦,帮助了我很多,也很感谢xenny师傅以及平台的所有其他贡献者,我们学校的CTFer现在基本都在这个平台做题,很好用,好评好评好评!🎆
赛题信息
- 计小鸡的秘密(misc)
- 考点:流量分析、图片隐写、宽高修改
- 难度:简单
- 题目描述:计小鸡好像有秘密告诉你?糟了,我没保存,只剩下流量包了!你自己找找吧,我去做下一道题了
- DNS Courier(misc)
- 考点:流量分析、已知明文攻击、二维码结构
- 难度:中等
- 题目描述:某内网主机被怀疑通过 DNS 流量“悄悄送出”了一份文件。某安全团队在边界处抓到了这段可疑流量,并将原始数据打包为 dns.pcap。请你还原被外带的数据,并找到其中的机密信息(flag格式为GCCCTF哦)
- hint:似乎有32位是某个文档的哈希值?怎么找到呢?
官方wp(算是)
题目:[GCCCTF 2025]计小鸡的秘密
考点:
#流量分析 #图片隐写 #宽高隐写
思路
下载附件后,得到一个pcap流量包,查看流量中协议分布,发现存在http,那么优先考虑分析http流
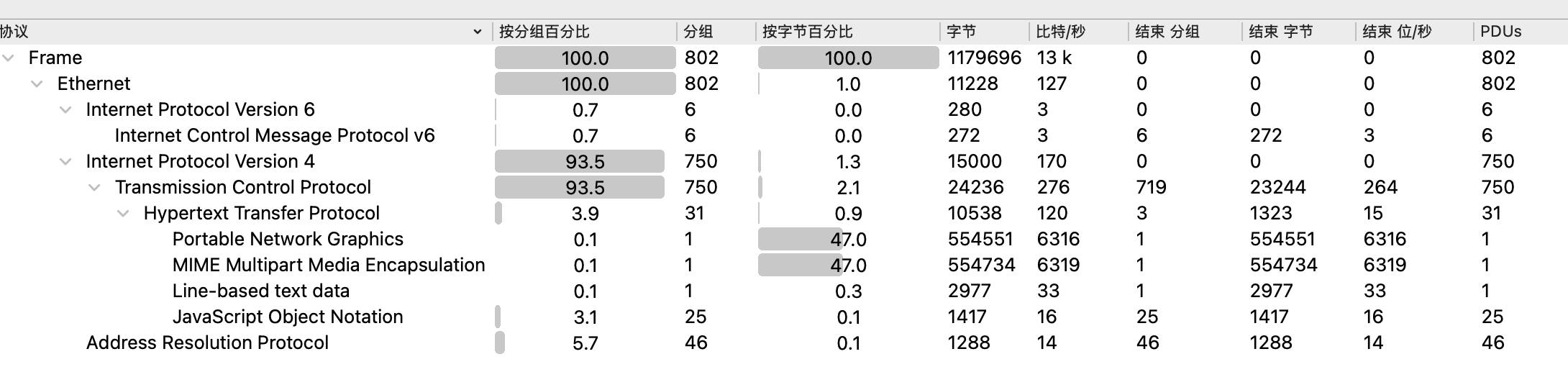
在过滤栏中输入http只保留http流,发现有一个流名称为1758942862494_secret.png,应该这里就是flag存在的地方,追踪流看一看
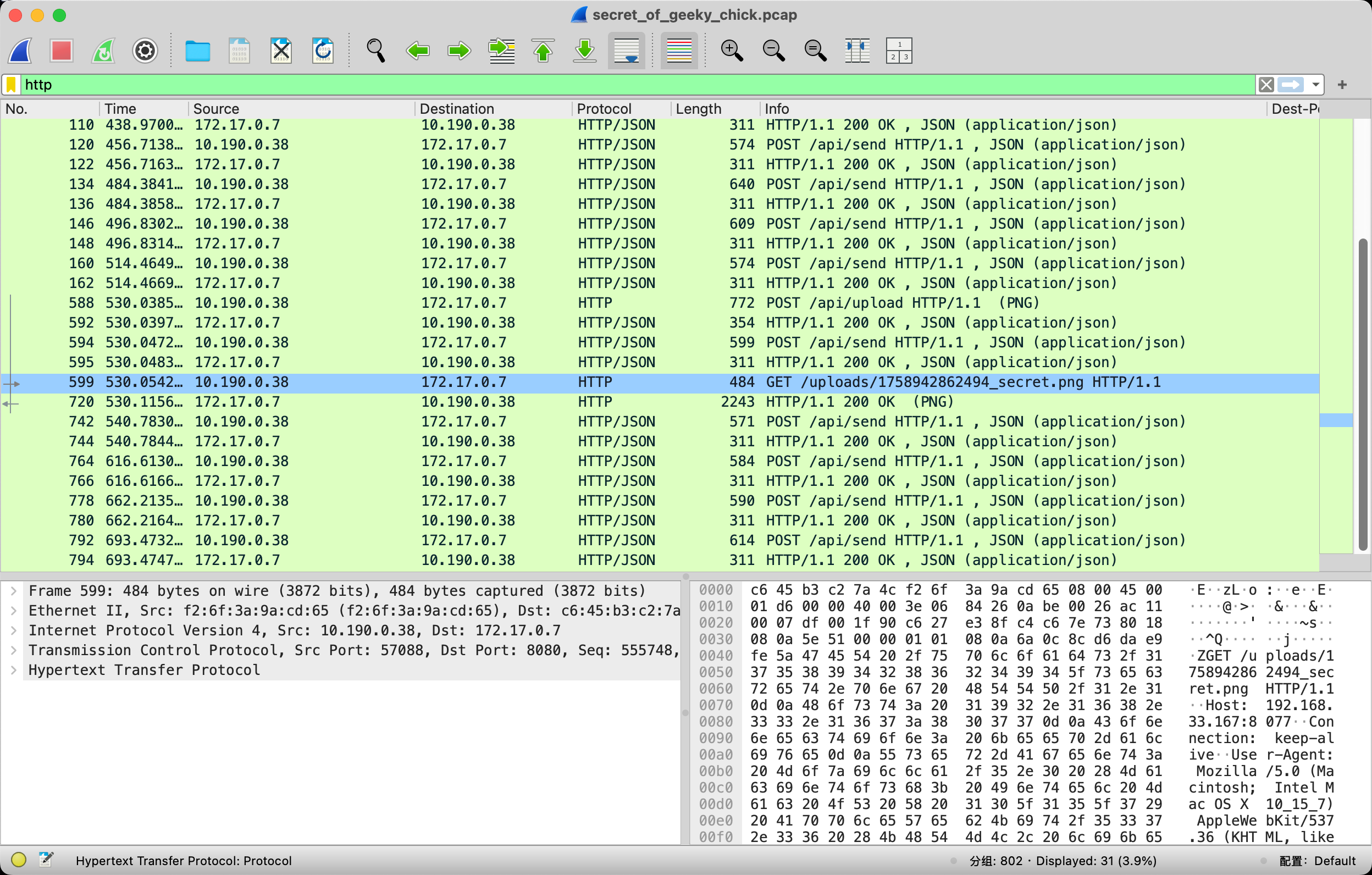
发现上传了一张图片,可以尝试导出

尝试将这张图片提取出来,使用binwalk和foremost都无法直接得到这张图片,又因为该图片是由http中传输的,尝试在http对象中直接导出,文件->导出对象->HTTP……
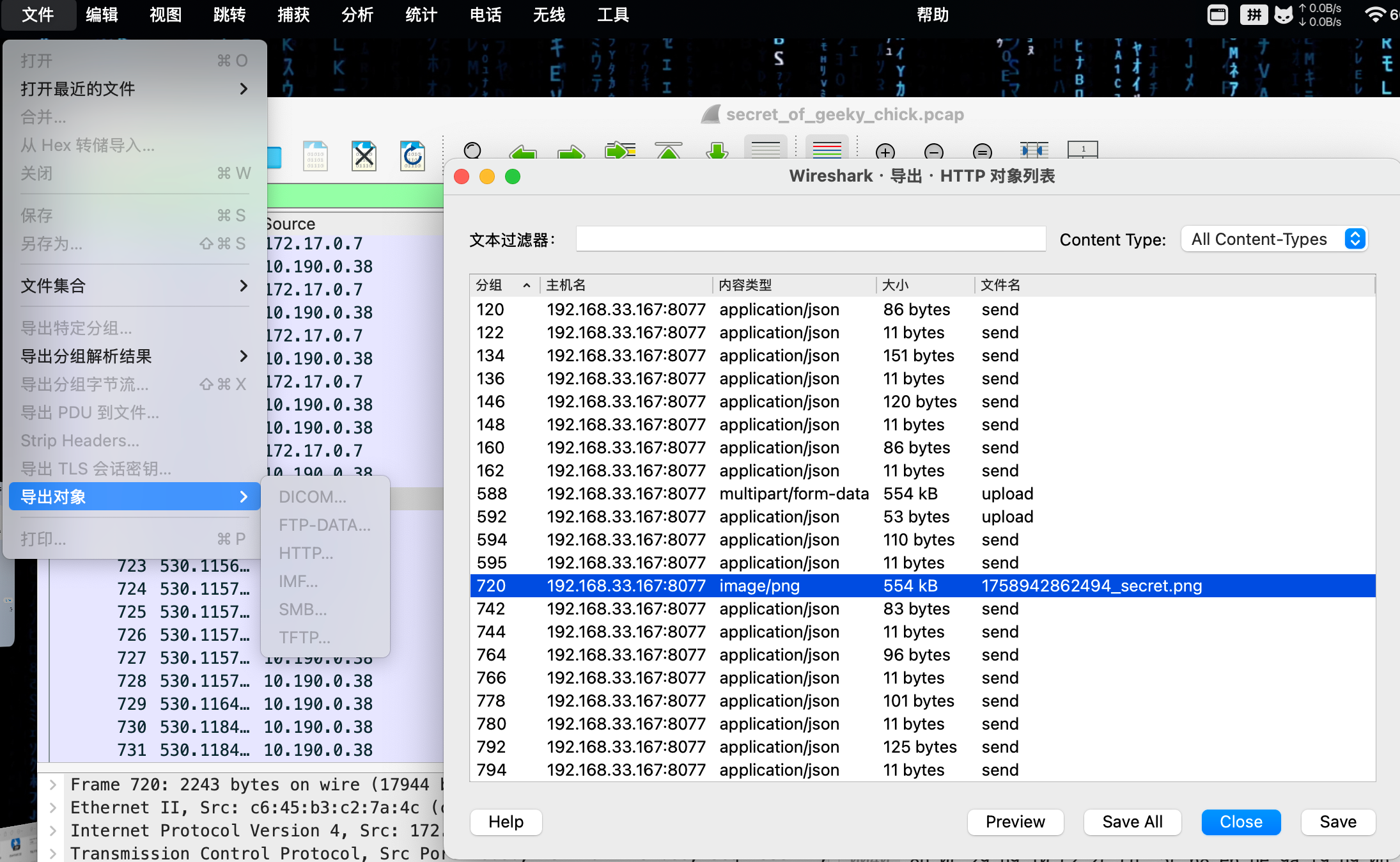
发现mac无法直接打开该图片,windows上显示会是乱码
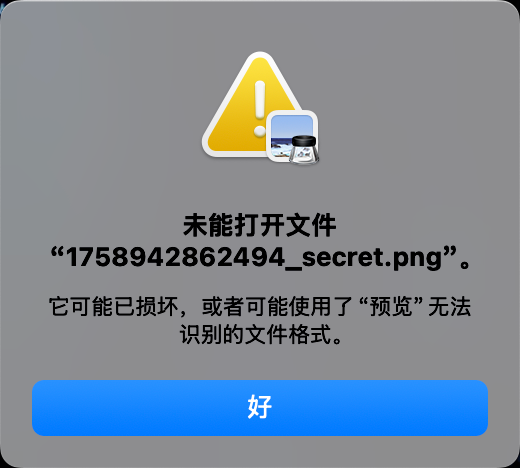
应该是图片结构遭到改变了,010editor打开后并未发现什么特别的,使用tweakpng打开图片发现报错
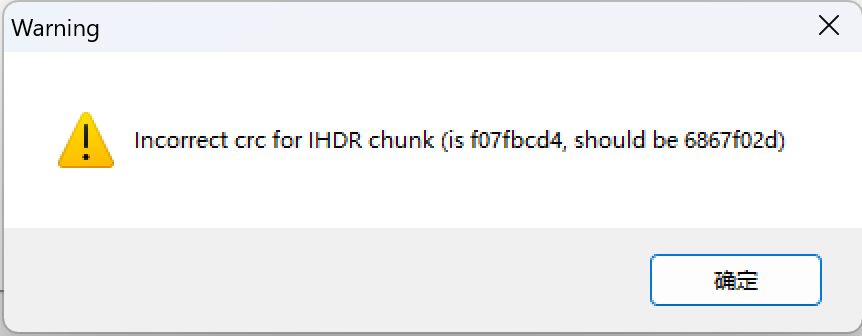
发现是IHDR块的crc校验不对,盲猜应该是宽高遭到了破坏(此外,其他http的流也也可以发现“看不到是因为变高”的提示),可以尝试自己编写crc爆破来计算正确的宽高,因为有很多的轮子了,此处不再实现,这里我使用曾哥的Deformed-Image-Restorer来尝试
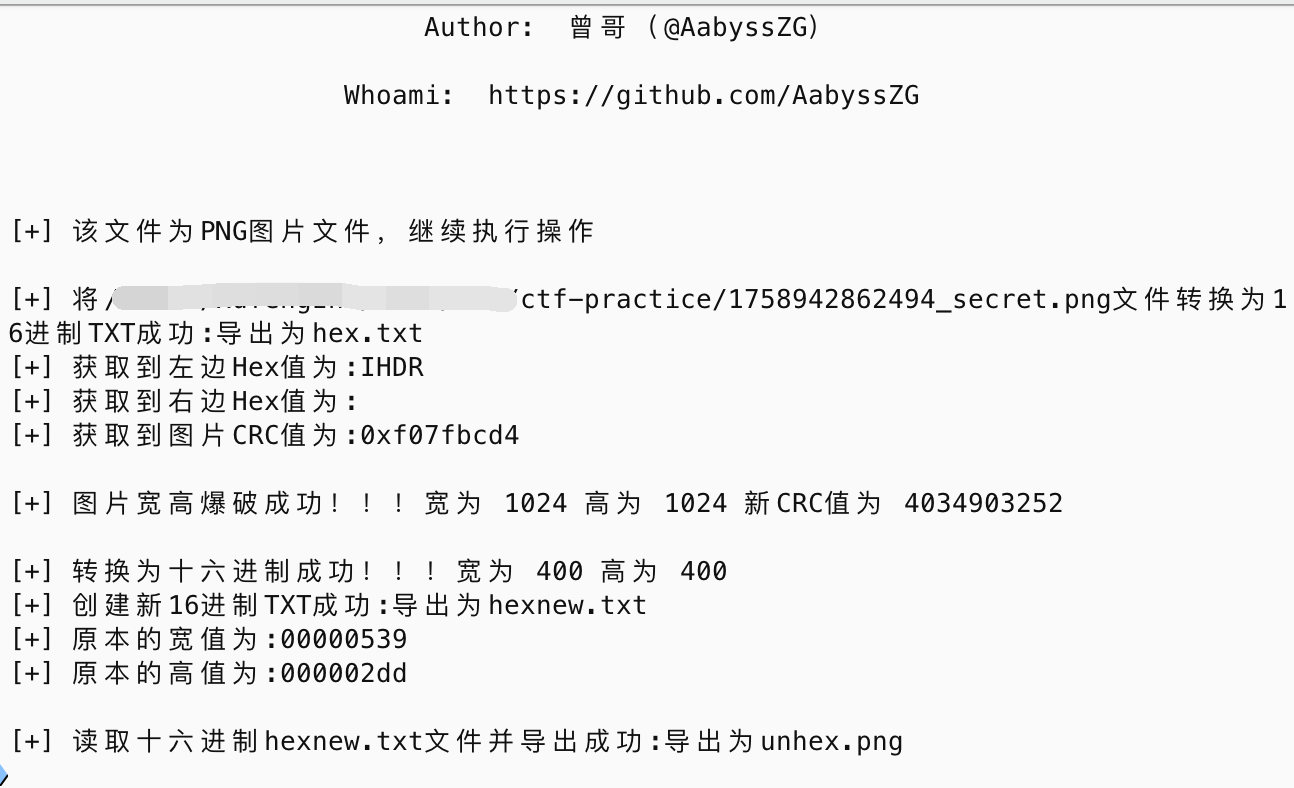
直接得到了flag

GCCCTF{W3lc0m3_2_GCCCTF!!!}
题目:[GCCCTF 2025]DNS Courier
考点:
#流量分析 #dns外带 #已知明文攻击 #二维码结构
思路:
下载附件后得到一个流量包,发现里面全是dns流量,大概看一眼,分析发现流量特征
- 流量包中前面部分和后面部分都存在一些噪声流量查询其他域名的
- 流量中间部分存在着以一串十六进制字符作为三级域名查询的
google.com的流量,看到504b0304猜测应该是外传了一个压缩包 - 涉及到传hex内容的请求是ip
192.168.33.167发送到8.8.8.8的 - 流量包中不止存在请求流量,还存在响应的流量
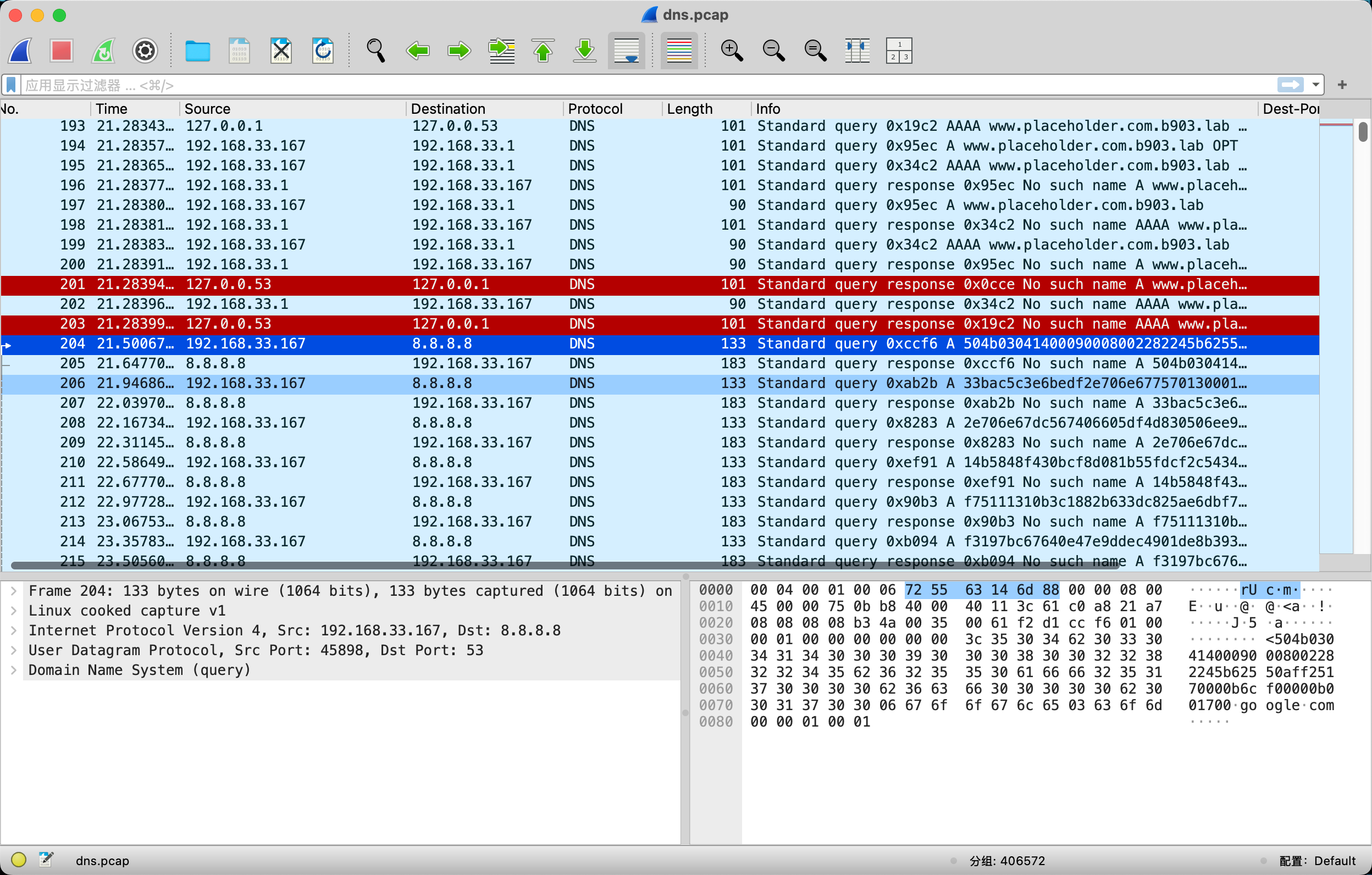
为了去除流量包中的干扰流量,使用如下过滤语句过滤出隐含信息的部分
dns.flags.response== 0&&ip.addr==8.8.8.8&&dns.qry.name contains "google.com" |
然后文件->导出分组解析结果->As csv……(此处是为了直观的查看流量内容同时方便编写脚本直接提取并拼接,或者可以直接编写脚本来处理pcap流量包获取zip压缩包,或者chatgpt5可以直接把压缩包脱出来),编写脚本来提取压缩包(交给ai即可完成,手搓也行)
此处提供一个我用ai生成的代码
import argparse |
得到压缩包会发现加密了,需要密码,注意到加密方法是ZipCrypto,压缩方法是Deflate,这种加密算法存在已知明文攻击的情况

当然可以尝试先去查找密码,会发现文件末尾有一段32位的数据,猜测可能是md5值
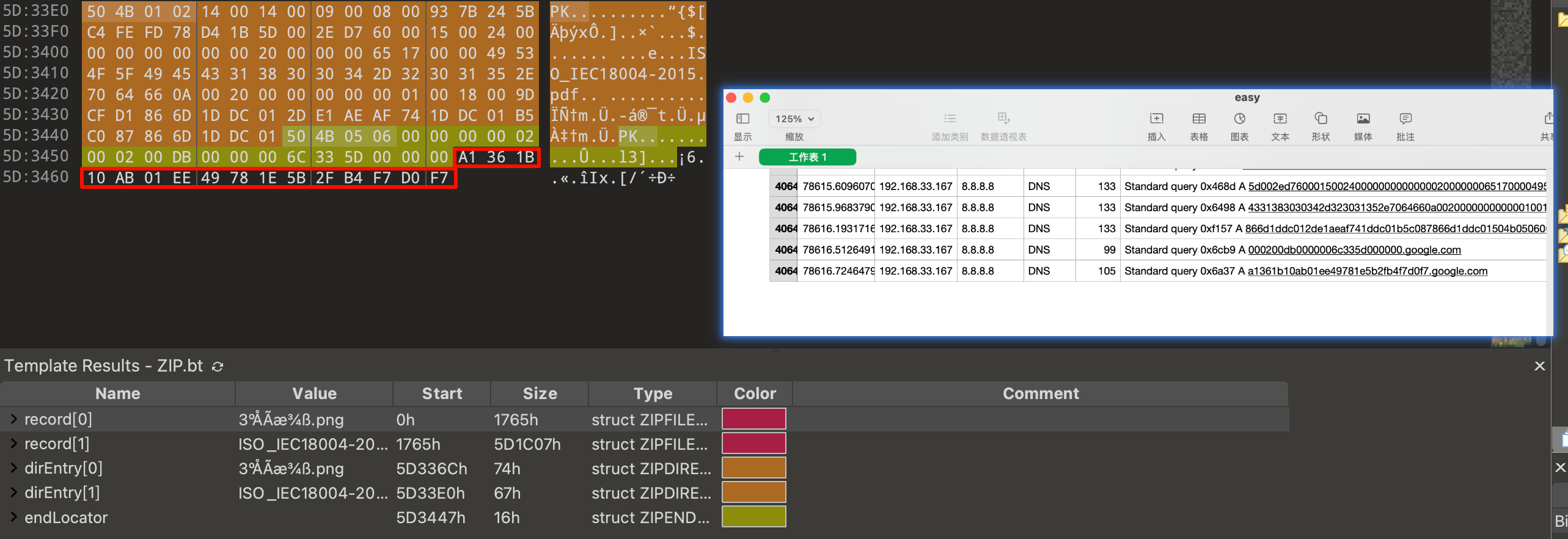
看到这个值可以尝试是否是压缩包密码,或者尝试在一些md5解密网站查找对应原文,但是会发现没有结果,均无法解开该压缩包,那么应该如何解开呢?我们之前看到压缩和加密方式意识到存在已知明文攻击的可能性,那么可以进行尝试,查看到压缩包里的内容有一个ISO_IEC开头的pdf文档,这个是由 国际标准化组织(ISO) 和 国际电工委员会(IEC) 联合制定的标准和规范文档,那么互联网上也许能找到该文件?并作为已知明文攻击的突破口
(后来发现没人解出题目便上了一个hint:似乎有32位是某个文档的哈希值?怎么找到呢?)
可以在virustotal搜索一下那串hash值a1361b10ab01ee49781e5b2fb4f7d0f7

发现文件末尾那串md5值是该pdf文档的,尝试在互联网里查找该文档,同时可以发现该文档是一个二维码标准文档
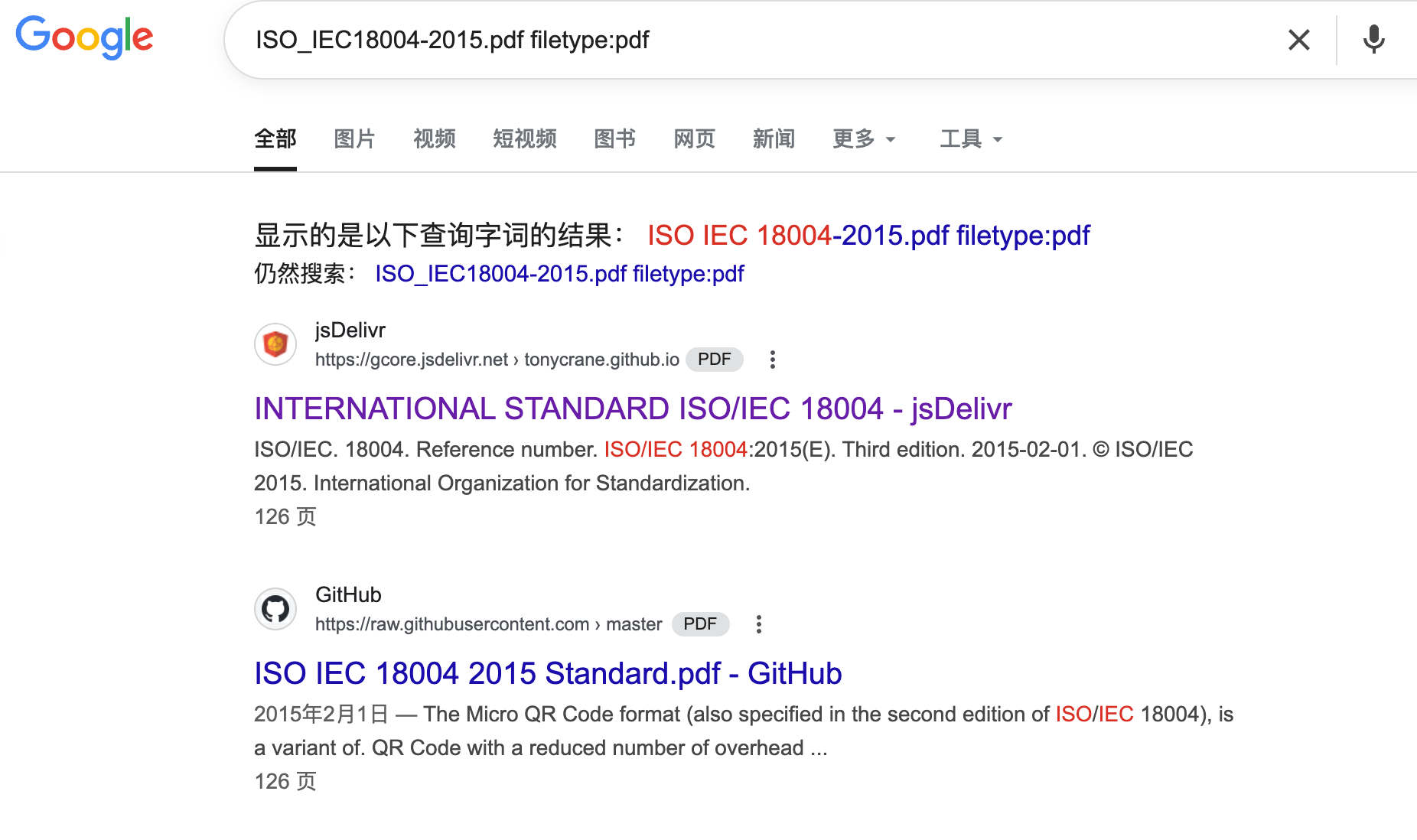
尝试几个后可以找到对应的pdf文档,下载下来后计算md5值发现一致即可用来已知明文攻击。
将获取到的pdf以相同的方式进行压缩,可以通过查看crc值校验
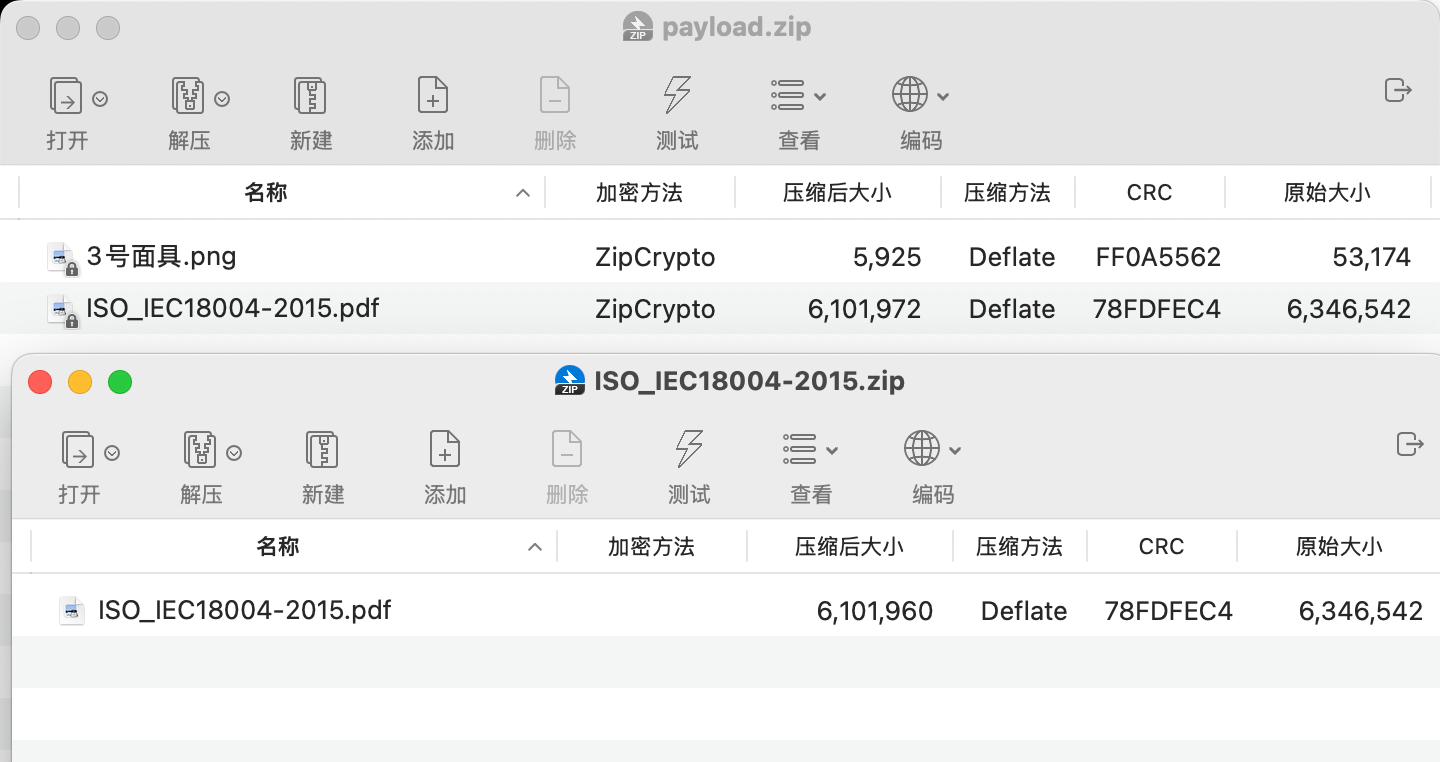
然后使用ARPHCR进行已知明文攻击即可
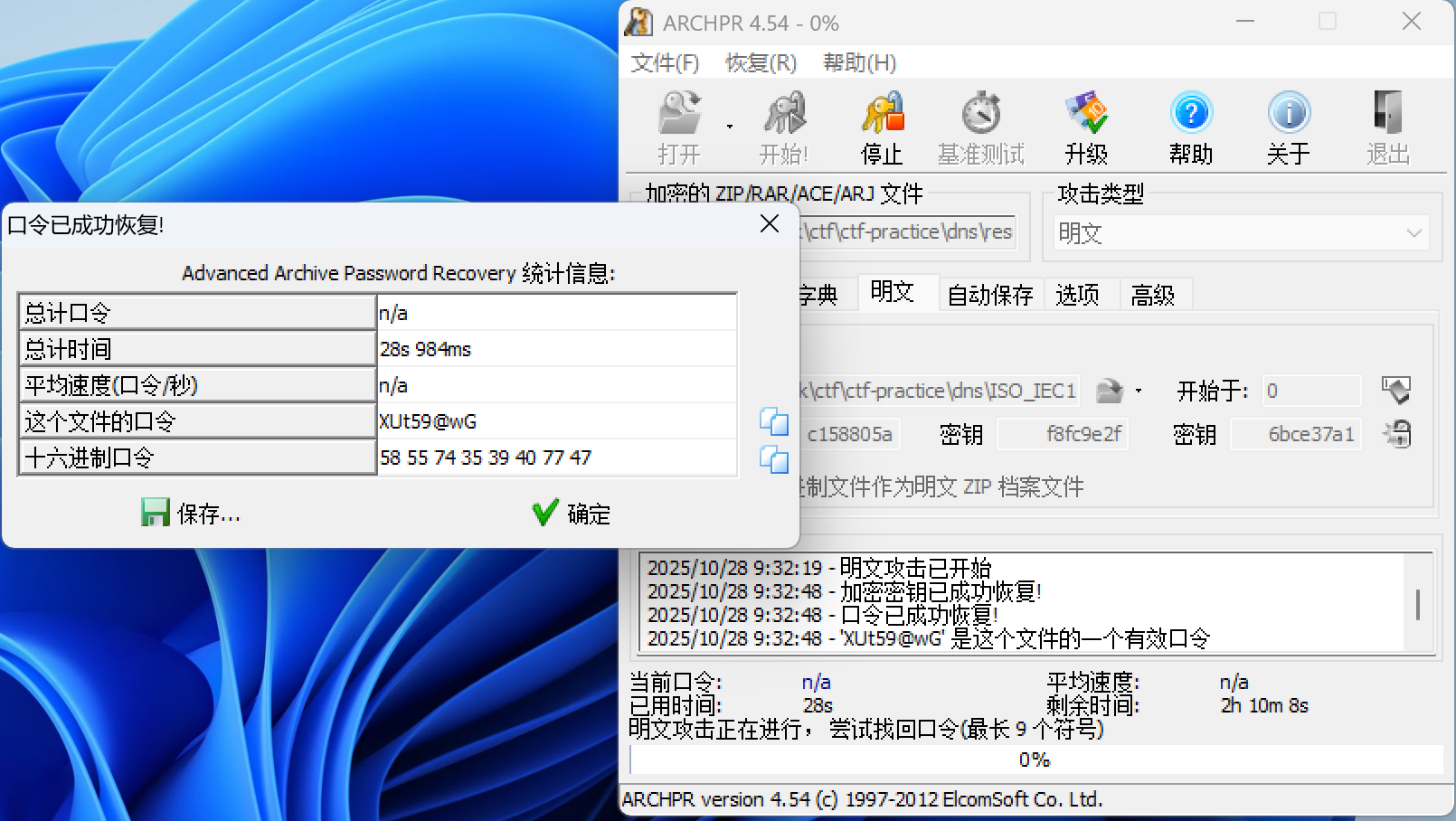
得到密码XUt59@wG
解开后得到一张3号面具.png的二维码图片,无法直接扫描,此处需要一点点小小的脑洞,面具英文(mask)同掩码,而如果熟悉二维码标准或者规范的,可以想到二维码的掩码模式,3号则其实给定了掩码3的模式,或者阅读二维码标准文档里也可发现该知识点
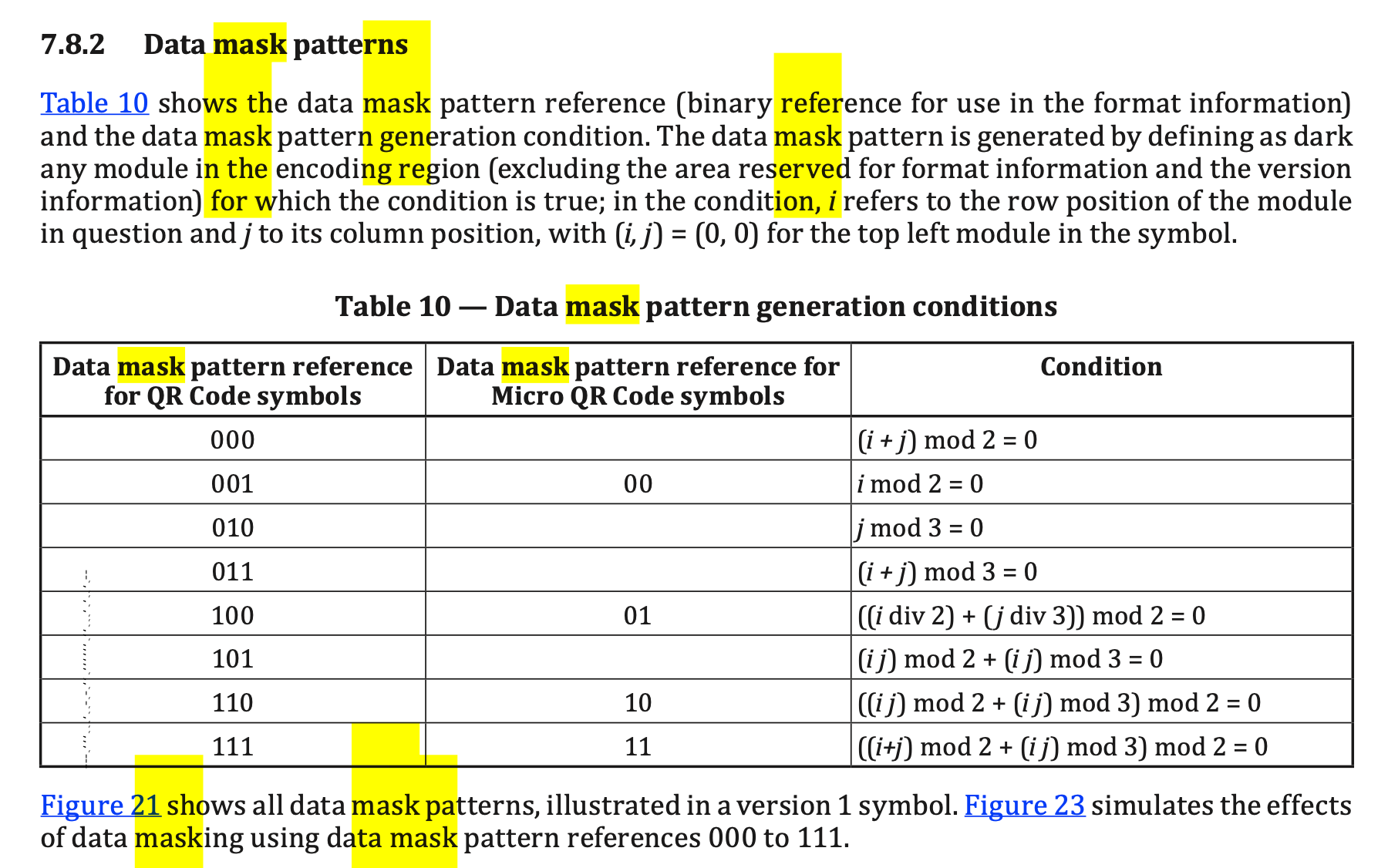
可以通过支持掩码扫描的工具获取,如Qrazybox,Tools->Data Masking->3->apply然后Tools->Extract QR Information拿到flag
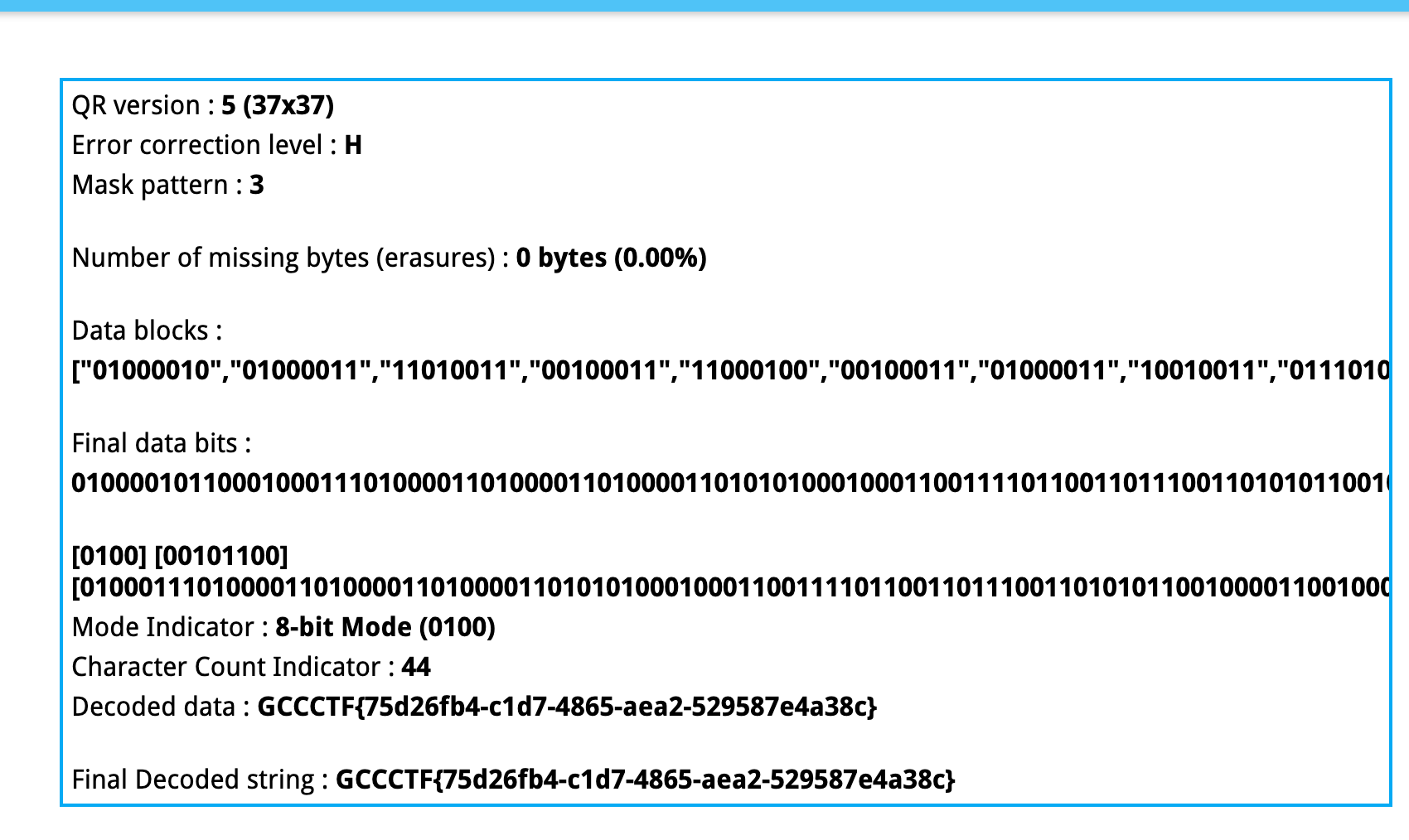
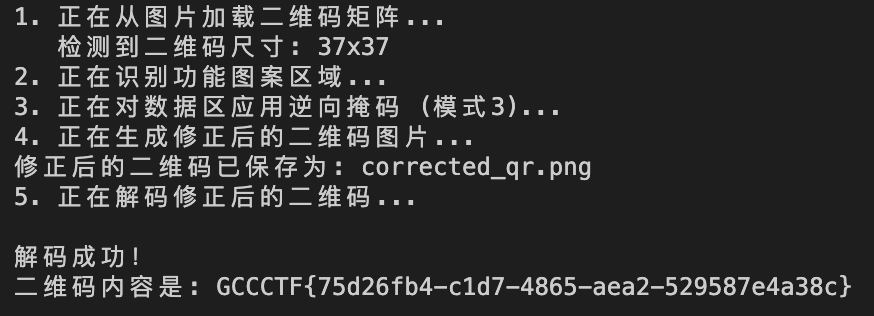
或者根据掩码方式(只对数据模块做 (i+j) % 3 == 0 的异或)编写一个脚本来获取信息
同样的,此处我给出一个ai编写的脚本示例:
import numpy as np |
参考链接:
题外话:
其实原本想出一道内存取证题,然后加上已知明文攻击和二维码的知识点的,但是制作检材过程中老遇到奇奇怪怪的问题,在打完陇剑杯后,参考了决赛第九轮的ezTraffic的方式,出了这样的一道题目
此外,在出题时尝试用ai去直接解题,发现chatgpt5太恐怖了,基本上直接能把思路完全给出来,如下是对应截图

总结一下经验
很新奇的体验,换了个角度去思考题目,我还是太菜了,只能出这样的套娃题,求师傅们轻喷,也希望我出的这些题目能够帮助到一些萌新?应该也许能帮助到刚入门的CTFer吧?
两年前懵懵懂懂地参加了学校第二届网安大赛的CTF赛道(算是我第一次的比赛经历了),记得当时赛前在攻防世界做了好久的web,其实也只算是模仿复现但没真的学到什么知识和技能吧,所以只做出来了一道ai题目的签到题,其他题一点思路也没有,纯坐牢hhhhhhh,拿了个大一新生特有的安慰奖。其实现在看来当时出的题目也蛮简单的。时间真的好快,我的变化也好大,从一开始的啥也不会,到现在能出题,能打比赛,能拿一些奖,成长了好多,也谢谢那些帮助过我的人,谢谢你们。